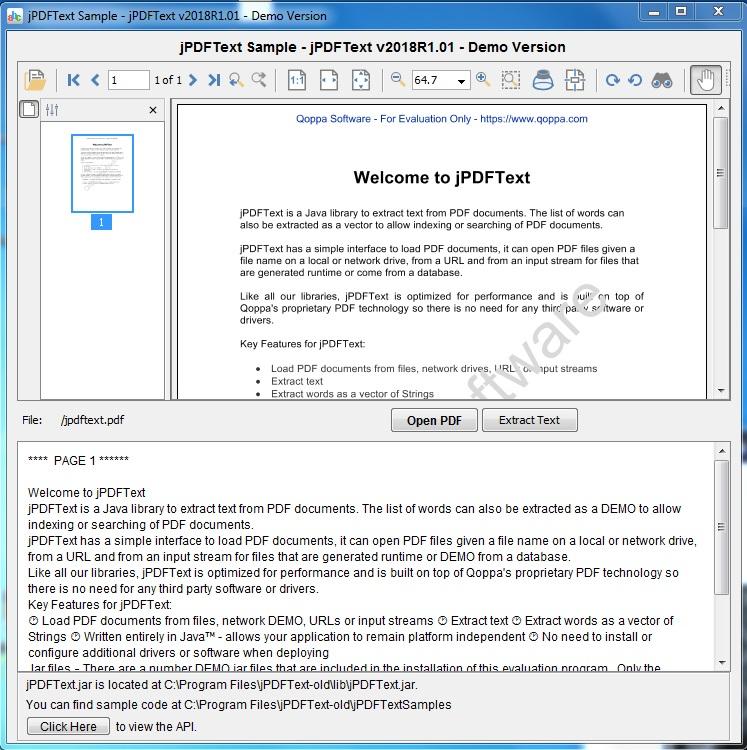
O jPDFText é uma biblioteca Java para extrair texto de documentos PDF. Com o jPDFText, documentos PDF podem ser processados para extrair o conteúdo textual para arquivamento, armazenamento, pesquisa ou indexação. O jPDFText é construído sobre a tecnologia PDF proprietária da Qoppas para que você não precise instalar nenhum software ou driver de terceiros. Como está escrito em Java, ele permite que seu aplicativo permaneça independente de plataforma e seja executado em Windows, Linux, Unix (Solaris, HP UX, IBM AIX), Mac OS X e qualquer outra plataforma que suporte o ambiente de tempo de execução Java.
Principais características:
Carregue documentos PDF de arquivos, unidades de rede, URLs ou fluxos de entrada.
Extrair texto na ordem de leitura lógica.
Extraia palavras como um vetor de Strings.
Funciona no Windows, Linux, Unix e Mac OS X (100% Java).
Não há necessidade de instalar ou configurar drivers ou softwares adicionais durante a implantação.
Testado no JDK 1.4.2 e acima.

Comentários não encontrado