
O Extractor Fusão PDF A imagem tem duas finalidades:
1. Para extrair todas as imagens individuais a partir de uma PDF (para recolher as imagens a partir de brochuras etc.) (limitado a imagens JPG até agora)
2. Para extrair todas as páginas de um PDF como representações de imagem JPEG de a página original
Nós lançamos um arquivo zip que contém todos os arquivos de programa eo código fonte a ver com como você por favor. Nós também lançaram uma imagem de instalação do Windows para quem não arquivos zip de manuseio confortável. O produto é Open Source sob a licença GPL.
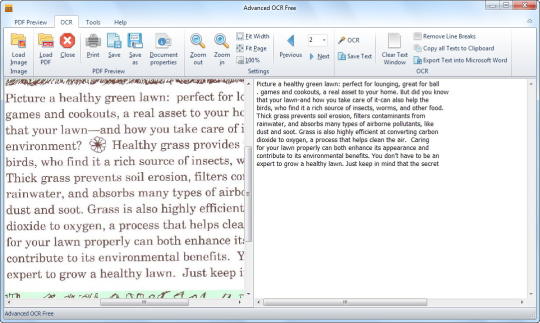
Criamos o PDF Image Extractor após uma experiência dolorosa tentando extrair imagens digitalizadas a partir de um relatório financeiro PDF para que eles pudessem ser colocados através de um processo de OCR e depois traduzidos usando o Google Docs. Decidimos, portanto, agrupar-se do trabalho que fizemos eo pequeno produto que nós escrevemos como código aberto e solte para todos. Ele é escrito em C # e se você quiser usar o código que vai trabalhar com o produto Visual Studio C # Express que é gratuito da Microsoft. . Basta adicionar a biblioteca iTextSharp incluído para seu projeto
Requisitos :
Microsoft .NET Framework 2.0

Comentários não encontrado