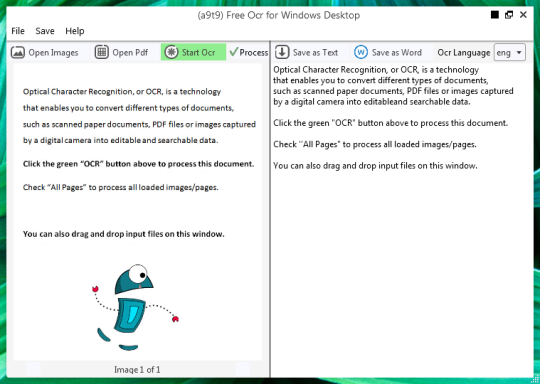
O software livre OCR para extrair texto de arquivos de imagem e itens PDF. A interface gráfica do usuário (GUI) para o motor Tesseract OCR.
A aplicação é simples de instalar e, mais importante, de uso livre, de código aberto e 100% de adware e spyware gratuito.
Você pode abrir um arquivo de imagem ou PDF. O conteúdo do arquivo de origem será exibido na janela da esquerda. Se o documento como mais do que uma página, ou se você abriu documentos com várias páginas, use as setas na parte inferior para alternar entre eles,
Você começa o OCR, clicando no botão verde OCR, e você vai ver o resultado na segunda janela da direita. Texto de saída pode ser salva como um arquivo de texto ou documento do Word.
Infelizmente, a qualidade de conversão não é tão grande. Por trás da cena ele usa o código-fonte aberto motor OCR Tesseract. A qualidade varia de língua para língua. - Então vá em frente e testar se é suficiente para suas necessidades
Para os desenvolvedores de software e geeks: The Free OCR para ferramenta Windows Desktop é, essencialmente, uma interface de usuário interface gráfica (GUI) para o motor Tesseract OCR. O código-fonte completo está disponível (licença GPL).
O motor de OCR do software suporta a seguinte redação OCR: Inglês, Francês, Italiano, Alemão, Espanhol, Português e Holandês brasileiro. A partir da versão 3, pode reconhecer árabe, búlgaro, catalão, chinês (simplificado e tradicional), croata, checo, dinamarquês, holandês, Inglês, Alemão (padrão e roteiro Fraktur), grego, finlandês, francês, hebraico, híndi, húngaro, indonésio, italiano, japonês, coreano, letão, lituano, norueguês, polonês, Português, Romeno, Russo, Sérvio, Eslovaco (standard e roteiro Fraktur), esloveno, espanhol, sueco, tagalo, Tamil, tailandês, turco, ucraniano e vietnamita.
Comentários não encontrado